The best way to be in sync with the other steps of a post production pipeline is to label frames with single timecodes, and it can be very useful to burn them onto reference clips. Here we see how to properly do so in Natron, which gives an introduction to expressions driven fields.

Timecode in Natron
Natron is a node based compositing software heavily inspired by Nuke, though free and open source. The tip described here also works in Nuke. I will assume that the reader is comfortable with the basics of the interface.
NB: For those of you who feel in a hurry, you can just get the expression code at the end of this post.
There is no timecode specific node, but a timecode is basically a line of text, so we'll use a Text node:
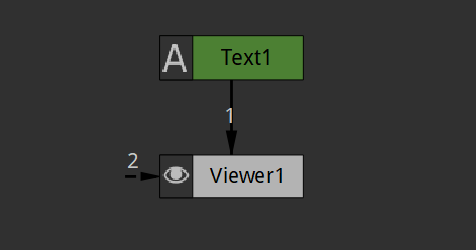
First create a text node
We'll start by setting up the text node so that the timecode is displayed in white over a black box in the bottom left-hand corner. Also merge the text over your footage, a simple grid in my example, in order to see what you're doing (and name your nodes correctly):
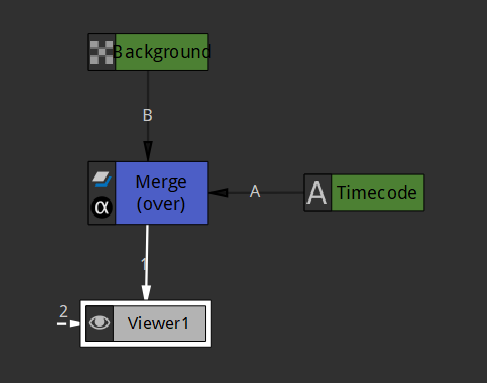
Merge the text over the background
Then put some test text and set the following quick options: a monospace font, a black non-transparent background, and auto-size to prevent the background from filling the whole screen. You could also draw a mask manually.
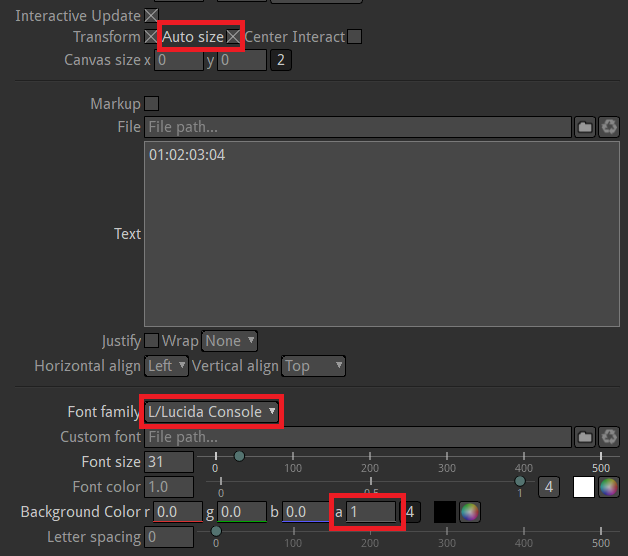
Text style options
Setting expressions
Now, instead of just typing a static text, we are going to generate it through a Python expression. For this, go to the properties of the text node (double click on it, then check out the right panel), and right click onto the Text field and go to "Set expression...":
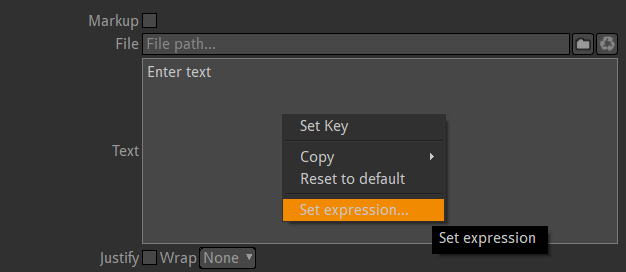
Set expression onto the Text field
This will pop up a new window with a text area, in which you can type some Python code that must evaluate into text. Bear in mind that for some reason the type must be correct, so typing 1 + 1 will not give "2". You'll have to convert it to a string using the str() function:
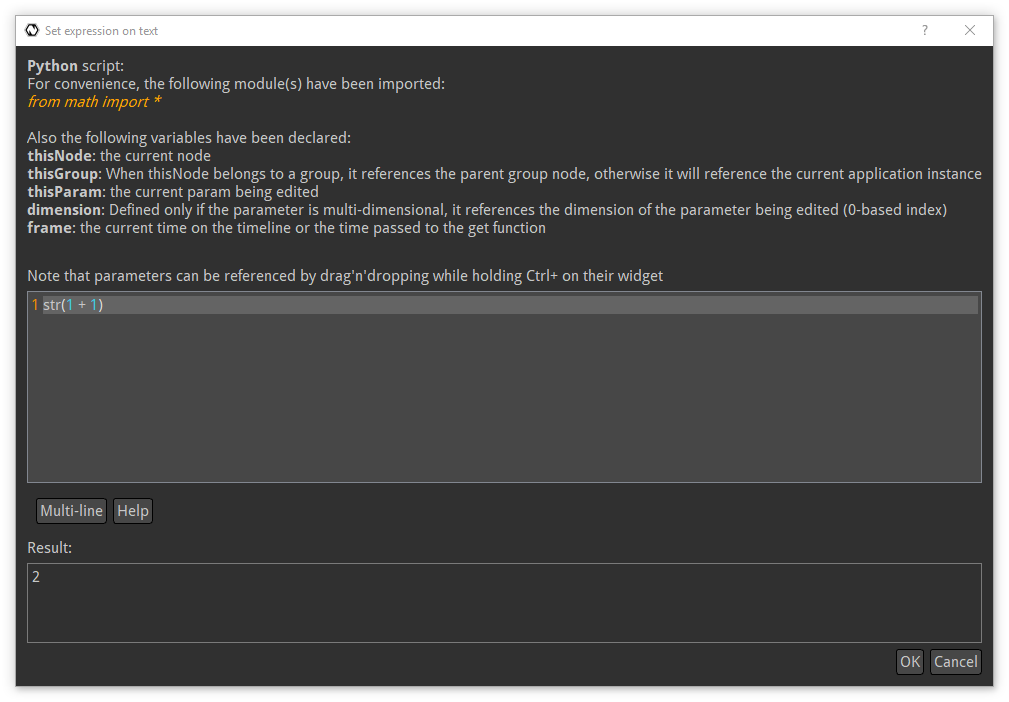
The expression window
NB: Using 1 + 1 would work if you were to set an expression on a numerical field.
Now, if you had a look at the bunch of text on top of the expression area, you may have noticed that there is a built-in frame variable available for use in the expression. This is the current frame number, as an integer. So, setting the expression to str(frame) should give you a basic counter.
Referencing other nodes
An important information that we are missing at this point is the frame rate. I haven't found a way to directly reference the project's frame rate, because unfortunately the neat "Ctrl+Drag" shortcut that allows to easily reference other node's fields in an expression does not work with the project settings panel. It works though to reference the frame rate of a read node. For instance you could put in your expression:
str(frame / Read1.frameRate.get())Your text is now the current time in seconds, and will automatically adapt to the frame rate of the read media. Moreover, you should see a green dependency link between your read node and the text node:
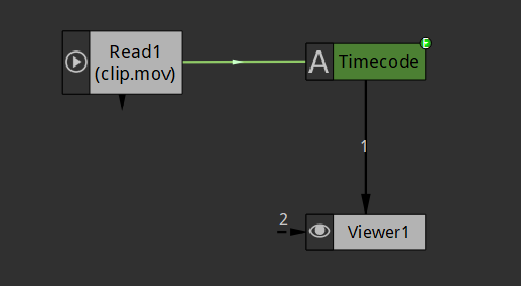
Expression dependency links are green
If you don't see it, press Shift+E or right-click in the node area and check the "Show Expression Links" option.
Multi-line expressions
Before going any further, we are going to need multi-line expressions. If you'd try to set the following expression:
frameRate = Read1.frameRate.get()
str(frame / frameRate)...then you'll get the following error:
ERROR: unexpected new line character '\n'This is because by default Natron expects the expression to hold in one single line. To fix this, there is a Multi-line button to toggle on:
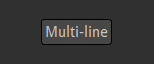
Toggle the Multi-line button on
Note to developers: Why doesn't it just detects that there are several lines??
And... this isn't enough. The single-line mode expects an expression, like 1 + 1 or frame / 24, but as soon as there are multiple lines, one has to manually store the value of interest in a magic variable called ret. Like "returned value" I guess. This is a bit hacky and loosely documented, but apparently the only way around. So in the end your multi-line expression should look like:
frameRate = Read1.frameRate.get()
ret = str(frame / frameRate)Formatting
What have left now is to format the text. Let's recall that a timecode is made of four 2-digits numbers, namely the hour, the minute, the second, and the frame index in the given second:
00:01:12:03
^^ frame
^^ second
^^ minute
^^ hourOne of the ways to format strings in Python is the % operator between a string and a tuple. For instance, "I am %d years old and %f meters high" % (age, height) will replace %d by the value of the age variable as an integer and %f by the value of the height variable casted as a float. In our case we need integers, so %d, and we also want to pad the number with zeros so that it is 2-digits long. The formatting sequence for this is %02d. So we came up with a template like:
h = 0
m = 1
s = 12
f = 03
ret = "%02d:%02d:%02d:%02d" % (h, m, s, f)Now we need to fill the variables h, m, s and f with their actual value, based on frame and frameRate.
This relies on divisions and modulos and is quite easy math, so I'll just do the beginning. If total number of frames elapsed is frame, then the total number of seconds is frame / frameRate and the remaining frames after this many seconds is frames % frameRate. Now the total number of seconds may exceed 60 so you'll do something similar for minutes, then hours. The full code looks like:
startTimecode = (00, 01, 12, 03) # for instance
frameRate = Read1.frameRate.get()
(oh, om, os, of) = startTimecode
offset = ((oh * 60 + om) * 60 + os) * frameRate + of - 1
i = frame + offset
h = i / (3600 * frameRate)
m = (i / (60 * frameRate)) % 60
s = (i / frameRate) % 60
f = i % frameRate
ret = "%02d:%02d:%02d:%02d" % (h, m, s, f)Note that I added an offset variable. Most of the time, the first frame of your current scene is not the frame at timecode 1. For instance, if the timecode of your initial frame is 00:01:12:03 and your frame rate is 24, this means that the index i at the first frame must be (01 * 60 + 12) * 24 + 03 = 1731, hence an offset of 1730.
About non integral frame rates
Nothing that we've done with the modulos works for non integral frame rates. More generally non integral frame rates introduce a bit of a mess when it comes about timecodes. You can have more information by reading this post by Hilda Saffari: Timecode and frame rates.
There is no general solution to handle those frame rates. One that always works is to round the frame rate up, using what is called a Non Drop Frame Timecode, but there will be a shift between the timecode and the actual clock time. Another solution used for 29.97 fps is a conventional Drop Frame Timecode were two frames are dropped every minute except every tenth minute. Here is a version of the expression implementing this behavior:
# Copyright (c) 2018 -- Elie Michel
# MIT Licensed -- Please credit if you use any substantial part of conversion math
startTimecode = (00, 01, 12, 03) # for instance
frameRate = 29.97
def tc2f(timecode):
"""for frameRate = 29.97"""
(oh, om, os, of) = timecode
o = ((oh * 60 + om) * 60 + os) * 30 + of
m = floor((o - 1.0) / (60 * 30))
return int(o - 2 * (m - floor(m / 10)))
def f2tc(frame):
frameRate = 29.97
i = frame + (floor((frame - 1) / (frameRate * 60)) - floor((frame - 1) / (frameRate * 600))) * 2
h = int(i / (3600 * 30))
m = int(i / (60 * 30)) % 60
s = int(i / 30) % 60
f = i % 30
return (h, m, s, f)
offset = tc2f(startTimecode) - 1
ret = "%02d:%02d:%02d;%02d" % f2tc(frame + offset)NB: A Drop Frame Timecode is signaled by the presence of a semi-colon (;) instead of a full colon (:) before the frame count.
Edit: Adding a start timecode to metadata
When your workflow relies on timecodes, it can be incredibly useful to specify the timecode at which a clip starts right within its metadata. Although Natron does not natively supports this in its write node, a timecode metadata can be added afterwards using ffmpeg:
ffmpeg -i INPUT.mov -c copy -timecode 01:02:03:04 OUTPUT.movThis will take the file INPUT.mov, copy its streams without changing their encoding (so really quick), add a header saying that the clip starts at timecode 01:02:03:04, and output everything to OUTPUT.mov.